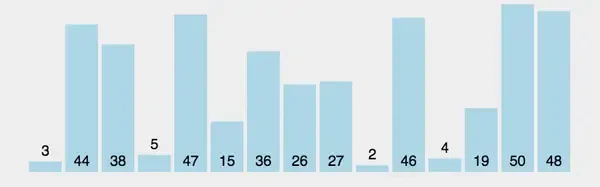
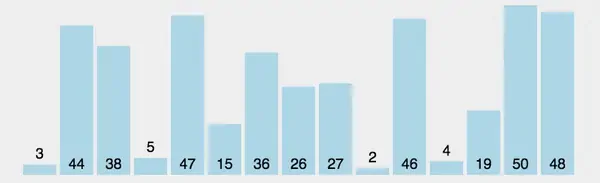
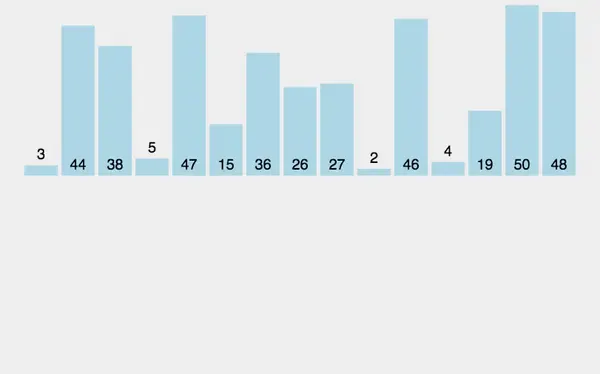
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
| #include <iostream>
// 辅助函数:交换数组中两个元素的位置
// (您的原始代码中调用了swap,但未提供定义,这里补充一个)
void swap(int tree[], int i, int j) {
int temp = tree[i];
tree[i] = tree[j];
tree[j] = temp;
}
// 辅助函数:打印数组内容
void printArray(int arr[], int n) {
for (int i = 0; i < n; ++i)
std::cout << arr[i] << " ";
std::cout << "\n";
}
/**
* @brief 核心调整函数 (sift down / 下沉)
* 用于维护最大堆的性质。假设一个节点的左右子树都已经是最大堆,
* 此函数可以保证以该节点为根的整棵树也满足最大堆性质。
* @param tree 存储堆的数组
* @param n 堆中元素的数量 (不是数组总大小,在排序阶段会变化)
* @param i 当前需要调整的子树的根节点下标
*/
void heapify(int tree[], int n, int i) {
// 递归出口或安全检查:如果节点索引超出范围,则返回
if (i >= n) return;
// 计算当前节点的左右子节点下标
// 在数组表示的完全二叉树中,节点i的左子节点为 2*i + 1,右子节点为 2*i + 2
int left = 2 * i + 1;
int right = 2 * i + 2;
// 假设当前父节点 i 的值最大
int max_index = i;
// 检查左子节点是否存在,并且其值是否大于当前最大值
if (left < n && tree[left] > tree[max_index]) {
// 如果是,则更新最大值节点的索引
max_index = left;
}
// 检查右子节点是否存在,并且其值是否大于当前最大值
if (right < n && tree[right] > tree[max_index]) {
// 如果是,则更新最大值节点的索引
max_index = right;
}
// 如果经过比较后,发现最大值的节点不是父节点 i
if (max_index != i) {
// 将父节点 i 与其最大的子节点交换
swap(tree, max_index, i);
// 交换后,原来位于 max_index 的较小值被换到了下面,
// 这可能会破坏以 max_index 为根的子树的最大堆性质。
// 因此,需要对这个子树进行递归的 heapify 调用,继续向下调整。
heapify(tree, n, max_index);
}
}
/**
* @brief 将一个无序数组构建成一个最大堆 (Max Heap)
* @param tree 待建堆的数组
* @param n 数组的长度
*/
void build_heap(int tree[], int n) {
// 找到最后一个非叶子节点。
// 在完全二叉树中,最后一个节点是 n-1,其父节点就是 (n-1 - 1) / 2 = n/2 - 1。
// 所有叶子节点天然满足堆的性质,所以我们从最后一个非叶子节点开始调整。
int last_non_leaf = (n - 2) / 2;
// 从最后一个非叶子节点开始,自下而上,自右向左,对每个节点调用 heapify
for (int i = last_non_leaf; i >= 0; i--) {
heapify(tree, n, i);
}
}
/**
* @brief 堆排序主函数
* @param tree 待排序的数组
* @param n 数组的长度
*/
void heap_sort(int tree[], int n) {
// --- 步骤一:建堆 ---
// 首先,将整个无序数组构建成一个最大堆。
// 完成后,数组的第一个元素 tree[0] 就是整个数组的最大值。
build_heap(tree, n);
// --- 步骤二:排序 ---
// 循环地从堆中取出最大元素,放到数组的末尾。
// i 是当前堆的最后一个元素的下标,也是未排序部分的边界。
for (int i = n - 1; i >= 0; i--) {
// 将堆顶元素(当前最大值 tree[0])与当前堆的末尾元素 tree[i] 交换。
// 这样,最大的元素就被放到了它最终应该在的位置。
swap(tree, i, 0);
// 交换后,堆顶的元素变了,破坏了最大堆的性质。
// 同时,堆的大小减 1 (因为末尾元素已经排好序,不再属于堆)。
// 所以,对大小为 i 的新堆,从根节点 0 开始,进行 heapify 调整,
// 重新找出剩余元素中的最大值并放到堆顶。
heapify(tree, i, 0);
}
}
// 主函数,用于测试
int main() {
int arr[] = {4, 10, 3, 5, 1, 9, 8};
int n = sizeof(arr) / sizeof(arr[0]);
std::cout << "Original array: ";
printArray(arr, n);
heap_sort(arr, n);
std::cout << "Sorted array: ";
printArray(arr, n);
return 0;
}
|